Limitations and challenges on the application of ML and DL
Applications of machine learning and deep learning techniques in many areas are rapidly growing, due to the flexibility of their algorithms and also because it is not required to model previously the scenario using a mathematical function.
Prototypes and computer systems are being developed, but there are still some bottlenecks to overcome. Although machine learning and deep learning algorithms are capable of capturing the complexity of several problems, in some cases the effective use of it depends on further research and development to increase the level of reliability before it can be used in the real world.In this section, we present some limitation and challenges on the application of artificial intelligence, especially machine learning and deep learning techniques, which should be addressed in future researches.
4.1 Generic approach
An algorithm does not interpret a problem the same way that humans do. It needs a mathematical equation to build a scenario that represents the reality. The mathematical equation is a representation of the reality and usually simplifies the problem to be solved, due to that incorporates mistakes and has limitations to be generalized. Because of it, the application of machine learning and deep learning techniques to control vector-borne diseases must be designed and/or trained for this specific purpose. There is no such generic approach: each problem has its own specificity and therefore must be treated with exclusivity.
4.2 Robust dataset
Another important limitation of machine learning and deep learning is the need of historical data to be used for algorithm training, learn from these data, and predict a reliable outcome. The availability, disposal, and variability of these existing data are crucial for the computer learning process. “Objects in realistic settings exhibit considerable variability, so to learn to recognize them, it is necessary to use much larger training sets [6].”
Entomology, for instance, has small dataset size available open source, which turns to be difficult to adapt the model and solve the problem with proper accuracy and reliability. Researchers should be aware that the application of machine learning and deep learning for zoonotic diseases must consider the building of a robust dataset.
4.3 Underfitting and overfitting
Underfitting and overfitting also need to be addressed during the use of machine learning and deep learning techniques. The first one relies when small data are presented in the training or the training does not run a sufficient number of epochs (learning cycles). In this case, the mathematical model is unable to capture the features complexity of the input provided and present a high error level in the output—too many wrong predictions when new data are presented.
Overfitting relies when the data presented have small variability or the training learning cycles are too much, and instead of reducing the error after each epoch, it starts to increase. To clarify the understanding, imagine a student who, among the elementary arithmetic operations (addition, subtraction, division, and multiplication), only dominates multiplication. If a test is presented only with questions to multiply numbers, probably the student will have a good grade, but you cannot measure his/her knowledge with this test. That exactly what happens with the computer if the variability of data is low. The training result might present a high accuracy, but in the real world, it is not reliable.
Figure 10 graphically shows underfitting and overfitting—validation error represents the predicting error when new data are presented.
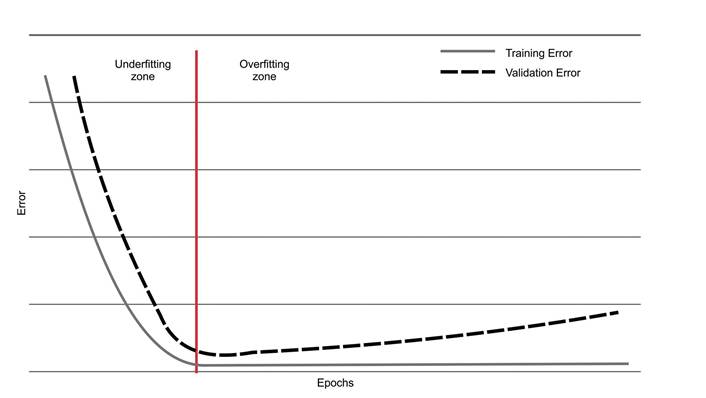
Figure 10.
Representation of underfitting and overfitting. uAdaptedfrom [1]”
There are some methods to reduce overfitting. “The easiest and most common method is to artificially enlarge the dataset [6].”
5.